
Introduction
At Softacus, we constantly strive to improve products and services. A very important part of the services offered for your infrastructure is monitoring. In addition to monitoring the basic system parameters of servers/VMs/ESXi, we offer the possibility of monitoring the IBM Jazz platform and its individual applications. This page aims to provide you with information about monitoring options for your IBM ELM applications and infrastructure. By being our customer, you have a unique opportunity to start monitoring your infrastructure at a high level. We can monitor the infrastructure that we manage - Softacus (local), or we can even set up the monitoring in the infrastructure that is deployed in your internal environments.
IBM Turbonomic Monthly Deminar

Apr 25, 2023 from 12:30 PM to 01:00 PM (ET)

Want to learn more about IBM Turbonomic hybrid cloud cost optimization features, capabilities, and use cases in a quick, no-pressure setting? Join the Turbonomic Monthly Deminar for an informative 15-minute demo followed by Q&A. We'll over an overview of the Turbonomic platform, walkthrough of the UI, and use cases including cloud cost optimization, cloud migration planning, on-prem virtualization optimization, and more.
- Get a detailed overview of Turbonomic from a Turbonomic expert
- Learn how Turbonomic uniquely automates decisions to minimize cloud costs while assuring application performance
- Ask our expert questions about Turbonomic
Key Speakers
Cognos Webinar - Dienstag, 18. April 2023, 13 - 14 Uhr CET

Dienstag, 18. April 2023, 13-14 Uhr
Titel: Liefern Sie die richtigen Daten an die richtigen Empfänger, schnell und übersichtlich mit IBM Cognos Analytics
Text: Um kluge Geschäftsentscheidungen zu treffen und ein fundiertes Marktverständnis zu erlangen, ist ein ständiger Zugang zu aktuellen Daten und Analysen unerlässlich. Unsere IBM Business Analytics-Lösungen bieten echte Kennzahlen und Erkenntnisse, die Ihnen die nötige Zuverlässigkeit für fundierte Entscheidungen liefern.
Die KI kann dabei auf Basis von Mustern und Trends in den Daten Prognosen erstellen, die dabei helfen, Entscheidungen zu treffen und zukünftige Entwicklungen vorherzusehen. Dies kann Unternehmen dabei unterstützen, strategische Entscheidungen zu treffen, ihre Leistung zu verbessern und sich auf kommende Herausforderungen vorzubereiten.
Unsere Präsentation "IBM Cognos Analytics mit Watson AI" gibt Ihnen einen Überblick über die neuesten Funktionen von Cognos Analytics und zeigt, wie IBM durch die Implementierung von künstlicher Intelligenz die Business Intelligence auch in Ihrem Unternehmen revolutionieren kann. Die neuen Funktionen beinhalten erweiterte Visualisierungsmöglichkeiten, neue Dashboards, Berichte, die Integration von Watson KI und viel mehr:
- Einfache und schnellere Self-Service-Funktionen
- Zusätzliche Datenquellen-Verbindungen
- Neue Exportmöglichkeiten von Visualisierungen und Landkarten
- Verbesserte PDF-Ausgabe für Dashboards
- Integration von Reports und Dashboards in Microsoft Teams
- Generierung von Auswertungen in natürlicher Sprache
Handeln Sie jetzt und melden Sie sich für unser exklusives Webinar an. Unser Experte Jens Bäumler von Apparo beantwortet alle Ihre Fragen und gibt Ihnen weitere wertvolle Einblicke.
Wir freuen uns auf Sie!
Link: https://www.ibm.com/events/reg/flow/ibm/g8z2vnmb/landing/page/landing
Speakers:
David Büchele - Project and Product Manager, Softacus GmbH
Softacus und sein Expertenteam haben sich auf Beratung, Service und Software-Entwicklung im Bereich IBM-Software spezialisiert und helfen ihren Kunden, die Sichtbarkeit und Transparenz bei der Lizenzierung und Verwaltung von kommerzieller Software zu verbessern.
Jens Bäumler - Cognos Berater und Trainer/IBM Champion 2022, Apparo GmbH
Die Kompetenz von Apparo ist durchgängig von der Datenbeschaffung, Datenaufbereitung und Sammlung (Data Warehouse) bis zur Auswertung durch Endanwender. Apparo unterstützt seine Kunden in allen Projektphasen von der Vorbereitung, Analyse, Umsetzung, Schulung bis zur Nachbereitung.
Maximo Wednesday Webinar | SaaS or Dedicated? Which Service is Right for you?


Our experts will give an in-depth comparison of Maximo Application Suite Dedicated and Maximo Application Suite as a Service and will dive into the preconditions, process, timeline, and roles and responsibilities for migrating workloads from a client-managed EAM installation to an IBM-managed MAS Dedicated or MAS SaaS solution. Come hear from our team who has been delivering hosting for Maximo for more than 20 years. Also, check out the free MAS trial: Click here for the MAS Trial
Softacus - IBM Ecosystem Award 2022 in Sustainability Software
We are pleased to announce that our company has been awarded at the IBM Ecosystem Kick-off DACH 2023 in the category Sustainability Software for exceptional growth in Engineering Lifecycle Management.
With tools and add-ons developed in-house for IBM products, Softacus has managed to demonstrate added value for customers and thus increase their competitiveness.
We look forward to continue working together with IBM to create innovative solutions that will have a positive impact on our society and the world!

REConf 24.-28. April 2023


Auch dieses Jahr wird Softacus bei der REConf, die vom 24 bis 28. April 2023 stattfindet, sein.
Die REConf (Requirements Engineering Conference) ist Europas führende Konferenz mit Schwerpunkt Requirements Engineering. Auf der Veranstaltung werden neue Methoden, Trends und Tools in Vorträgen, Diskussionsrunden und Workshops diskutiert.
Am zweiten Tag der Konferenz (25 April) um 16:00 Uhr wird unser Solution Director, Jan Jancar, zusammen mit Peter Schedl von IBM, einen Vortrag zum Thema "Traceability - das Salz in der Suppe" halten.
Anforderungen sind der Ausgangspunkt der Entwicklung und somit auch der Traceability für alle Entwicklungsdaten. Projekte stellen heute bereits sicher, dass alle Kundenanforderungen in Systemanforderungen überführt wurden und Testfälle spezifiziert sind. Nicht selbstverständlich ist die Traceability in Verbindung mit KPI’s oder der toolgestützten Impactanalyse bei sich ändernden Anforderungen.
Softacus zeigt gemeinsam mit IBM Best Practices wie sich solche Szenarien mit DOORS und der Engineering Lifecycle Management Lösung einfach abbilden lassen.
Melden Sie sich für RECconf 2023 hier an: https://www.hood-group.com/reconf/anmeldung

DOORS Next provides great functionalities for managing requirements within your team, but as your project grows sooner or later you need to export and import the data using external formats.
For DOORS Next data the first format to think of is project template (or component template, in case if configuration management feature is enabled in RM). Content of template can be set up to include different types of data but all items of included types will be included to a template (e.g. you can include artifacts to a template - and it means that all folders will be added to a template). Another option is the ReqIF package - it allows interchange requirements between requirements management platforms which are compatible with ReqIF, with more data selection options (e.g. you can include only certain artifacts or modules).
CSV/spreadsheet format is also an option to export and import data to DOORS Next, and this article provides some details on these functions.
The purpose of this article is to describe several cases of CSV/spreadsheet import and export, prerequisites and limitations.
Import from CSV/spreadsheet is initiated from the ‘Create’ drop-down list, ‘Import Artifact…’ item (Figure 1).

Figure 1
On the ‘Import’ form several options are listed, CSV/spreadsheet import is the second (Figure 2).

Figure 2
Mandatory attributes
On the second step of import requirements action after choosing CSV/spreadsheet import the list of import options is displayed. Depending on chosen location for import and required actions CSV/spreadsheet file must include certain attributes. Import will not proceed if mandatory attributes are missing. Mandatory for all cases attribute is ‘Artifact Type’.
If the purpose of import is creation of new artifacts - CSV/spreadsheet file must include either Name or Primary Text attribute. In case if Primary Text is used - Name attribute will be updated automatically with Primary Text value (with Name attribute type constraints).
If the purpose of import includes update of existing artifacts - then ‘ID’ of artifacts becomes mandatory attribute, and so is any of attributes which are supposed to be updates (could be Primary Text or any custom attribute).

Figure 3
Another import option which defines mandatory attributes is location. With CSV/spreadsheet import artifacts can be imported to a selected folder (as base artifacts) or to a module - in this case import allows to update module structure (positioning of artifacts in module) and module specific attributes.

Figure 4
If you want to import an artifact into a module - in the simplest case, create a new artifact - you need to include module specific attributes to a spreadsheet. They are:
- isHeading - boolean value, related to module specific option of an artifact, regardless of artifact type (must be set to ‘true’ to use as heading in a module, could be empty or ‘false’ in other case
- parentBinding - ID of parent artifact (an artifact to which inserted artifact will be demoted) for the new one. The value is empty if an artifact is on the top of module hierarchy or contains ID of ‘parent’ for the current artifact (e.g. Heading of a chapter to which current artifact is related)
As well as for base artifact import (in other words import into a folder) you have options to update and/or create new artifacts, and if you are going to update existing artifacts - you need to have an ID attribute in your file.
For more precise positioning of inserted artifact you can have in your file existing artifact before which you expect your artifact to appear in a module, but this is not mandatory to perform import of artifact to a module.
Another special case which requires not yet mentioned mandatory data in a file is deletion of artifacts from a module with CSV/spreadsheet import. On Figure 4 you can see that when ‘Import requirements into a module’ is selected an additional checkbox is available below this option - ‘Delete artifacts from the module…’. This option allows you to exclude artifacts from the module when you upload your file. To do this you need to use a file created by export from the module you are planning to update and besides excluding artifacts which are not expected to be in the module you need to keep the ‘METADATA’ section in your file.

Figure 5
Use cases
There are several use cases which can be covered with CSV/spreadsheet Import, some of them are explained below.
Links creation
You can use CSV/spreadsheet import for links creation, and here there are options. The very straightforward option is to literally insert links directly. In this case you can use a spreadsheet column to build a link to another item (either another artifact in DOORS Next or work item in EWM application or test artifact in ETM). For EWM and ETM this is the main option, you can better understand the format of a spreadsheet after exporting some samples. It can help you to build your spreadsheet for importing links either for base artifacts or for artifacts in a module - depending on the import option you use. For this case CSV/spreadsheet can solve creation of links to the same targets from the new destination (e.g. if you moved your requirements to some new component or application and you need to relink them to the same work items and test artifacts). It is possible only to add new links, CSV/spreadsheet import won’t remove existing links. The format of this attribute is shown no Figure 6 - it includes column name, defining link type and it’s direction, the attributes value consists of id (or pair of module id and artifact id for link to/from artifact in a module as shown on Figure 6), name of artifact and URI of artifact. So it is quite not trivial to reproduce such values outside of DOORS Next.

Figure 6
For links to other DOORS Next artifacts you can use CSV/spreadsheet to prepare your requirements for linking via ‘Link by Attribute’ feature. In this case you need to have a special attribute which is supposed to hold IDs of artifacts to be linked. And you can fill values of this attribute via spreadsheet. Depending on your linking policy and needs (linking to base artifacts or linking to artifacts in certain modules) you will use either IDs of artifacts you need to link to (e.g. 12345 is an ID of artifact you want to build a link to) or pairs of module ID and artifact ID (e.g. 23456.34567 - where 23456 is ID of a module and 34567 is ID of an artifact in this module when you want to create a link to a modular artifact). After successful import of these values you can proceed with using the ‘Link by Attribute’ feature, which can be invoked on a view or selection of artifacts.

Figure 6
Tables in Primary Text
You can export tables for import to CSV - but it will be only pseudo-graphics. Some tables can be exported and imported via spreadsheet, and the limitation for this case is size of table. If your table is exceeding the limitation - you will be notified with an alert (see Figure 7). Originally built in DOORS Next tables from our experience look more lean.

Figure 7
If a table was successfully exported to a spreadsheet - you should use an original file for import (copy-pasting the content can break the structure).
Embedded artifacts
Embedded artifacts can be handled via spreadsheet but they must be present at destination prior to running spreadsheet import.
Tips and tricks
Few general tips which could help you when working with CSV/spreadsheet import and export:
- Use column names from exported spreadsheets to be sure they are right
- If you are importing values of modular artifacts (pairs of IDs separated with dots) - check formatting of cells, by default they might be decided by spreadsheet as numbers with decimals and therefore trimmed
- If you are sure you are doing everything right but import fails - try switching to English locale
- If you need to exclude some artifacts from a module - be sure to keep the ‘METADATA’ section from the initial state of a module (it includes list of IDs of artifacts), otherwise ‘delete artifacts from the module’ option won’t work
- When you import from a spreadsheet file - only first tab will be processed by DNG
- Use Arial font size 10 to keep DOORS Next automatically formatting headings in modules
- Reasons to decide module as a location (besides need to update module structure) could be links and tags for modular artifacts
- Use a changeset for bulk changes (a sort of which CSV/spreadsheet import is) to keep an option to quickly revert changes
- If you need to handle spreadsheet import with support of embedded artifacts - reach us for ready to go script for this case
- Be careful with enumeration values - not really visible space in spreadsheet attribute can break import operation

Introduction
The history is an important part of the requirements management tool and the purpose of this article is to explain functions and capabilities of DOORS Next for working with history of requirements.
Artifact revisions
On the very basic level history of requirements management items in DOORS Next is organized on artifacts level and is presented as revisions and audit history. This information is accessible for artifacts via ‘Open history’ action in the menu (Figure 1).

Figure 1
The first tab you see when you open history is ‘Revisions’, it is splitted on ‘Today’, ‘Yesterday’, ‘Past week’, ‘Past month’ and ‘Earlier’ sections which include different versions of an artifact and baselines of project area or component. When you switch to the ‘Audit history’ tab you see only versions of a current artifact with explanation of actions performed on it and changes which were created with information on date and time and author of it.

Figure 2
Revisions can be restored to the current state. To revert the requirement to a previous state you need to use artifact menu and select ‘Restore’ action (Figure 3).

Figure 3
History in attributes
Another source of history of an artifact are system attributes, which preserve information on date and time of creation and modification of an artifact and a user who created and modified an artifact. These attributes are updated by the application on creation of an artifact (Created On for date and time of creation and Created By for username) and Modified On and Modified by for the latest modification. Additionally, if you use ReqIF import to add artifacts, attributes with the prefix ‘Foreign’ will show you related information from the source (Figure 4). Attributes with prefix ‘Foreign’ will display timestamps and usernames from the source of imported requirements.

Figure 4
Of course, a revision list and attributes of a single artifact is not enough to manage requirements history, so versions of artifacts are aggregated to baselines. The first kind of baselines is a DOORS Next baseline, in other words it can be explained as a snapshot which includes certain revisions of artifacts. Baselines are created to preserve some agreed state of requirements, artifacts cannot be edited in a baseline (Figure 5).

Figure 5
Module revisions
When we are talking about artifact revisions It is meaningful to mention that module revisions are specific - they are created when module structure is changed (a set and / or order of included artifacts) or attributes of a module as an artifact itself. So when you edit an artifact in module context without changing position of this artifact in module (Figure 6, marked with green color) - you do not create new revision of module automatically. Only insertion of new artifact, editing module attributes (Figure 6, marked with purple) or moving artifacts within a module will update attributes of a module with date & time and contributor name. To capture the complete state of a module you need to create a DOORS Next baseline.

Figure 6
History in streams and changesets
DOORS Next with configuration management capabilities has more options to manage history of requirements. First of all - streams, which allow you to have parallel timelines for different variants of requirements. All requirements in DOORS Next have their initial stream, which is the default timeline for requirements changes. DOORS Next has an option to create a parallel timeline using additional streams, which is mostly used to manage variants of requirements.In this case usually some existing version of requirements is used as an initial state for a new stream. And changes of artifacts in a new stream will not affect the initial stream - revisions of artifacts created in a new stream are visible only in this stream unless the user initiates synchronization (see Figure 7, the module is shown in two different streams - stream names and changed artifact are coloured with purple). During synchronization the user has options with merging approaches, and one of them is using changesets, which are explained below.

Figure 7
Changesets are another kind of data set in DOORS Next which can be observed in the audit history. There are two types of changesets - user created changeset (name of changeset in this case is specified by user) and internal changeset, which is a reference for changes in the audit history. Internal changesets can be found in the audit history and can be also used as an option to deliver changes across streams. Created by user changesets aggregate small changesets automatically created by DOORS Next, which can be found in audit history and in the merging menu when you deliver changes from one stream to another. Both types of changesets can be found on stream’s page, and if a stream is allowed to be edited only via changesets - it means, users are forced to create a changeset to edit requirements in a stream - a list of changesets of a stream gives you a good representation of history for a stream (Figure 8).

Figure 8
Baselines
Another functionality to manage history is Global Configuration baseline. When you enable DOORS Next project area for configuration management, links between requirements in different components are created via Global Configuration stream - you need to switch to Global Configuration context to create a link across DOORS Next components and also to see such links. As each component is baselined independently in DOORS Next, in order to preserve cross-component linkage state you need to create a Global Configuration baseline. When you perform this action, baselines are created on each component level automatically and included to a Global Configuration baseline. Switching to this baseline in the future will show you the exact state of linking at the moment of global baseline creation - proper links between proper revisions of artifacts (Figure 9).

Figure 9
Compare configuration
DNG functionality of configuration comparison can be used between streams, baselines and changesets and provides overview of changes in history and/or across variants on several layers - type system (data model), folder structure, and the data itself (including module structure, artifacts text and attribute values, links) with an option to filter changes (Figure 10).

Figure 10
Tips and tricks
- As mentioned above, baselines are created on component level (or project area level if project area is not enabled for configuration management). When number of baselines grows, some maintenance of baselines is required - to shorten the list of baselines, some of them need to be archived
- To help users with navigation in list of baselines we provide special widget, which filters from the flat baseline list those baselines which were created in a certain module context
- Links operations to not modify artifacts, link changes can be found in configuration comparison results
- To support filtering history events in a module scope Softacus provides special widget, which allows to get list of artifacts modified in a module scope
- Using change sets to update streams with link from change sets to Engineering Workflow Management work items adds context for history with explanation of a reason for changes
Softacus - one of the Top 10 IBM Solution Companies for 2022

Softacus has been selected as one of the Top 10 IBM Solution providers for 2022 by the CIOApplications Europe - a popular European magazine on innovations and technology.
In this article, featured in the magazine in December 2022, our Solution Director, Jan Jancar, talks about the challenges engineering teams are facing nowadays and how Softacus and the IBM Engineering Lifecycle Management solution help organizations improve collaboration among software and system developers, increasing efficiency and product quality.

Introduction
IBM® Rational® DOORS® Next Generation is consistently one of the best requirements management tools out there. One of its biggest strengths is the opportunity to expand its capabilities by the people using it, so that they can utilize it to its fullest. Whether you are someone who already uses IBM® Rational® DOORS® Next Generation on a regular basis or someone who is considering using it, the knowledge of how you can optimize your work environment is the key to peak productivity in the workplace.
Purpose of the article - OS Gadgets
This article will be delving into how you can extend IBM® Rational® DOORS® Next Generation behavior with JavaScript, in particular we will be focusing on OpenSocial gadgets (widgets that are created following OpenSocial standards), as DOORS Next offers its users a JavaScript API which enables OpenSocial gadgets to automate intricate operations and work with the requirement data.

Here is how an OpenSocial Gadget is defined:
It can be defined in an XML file composed of two parts. The first one is Preferences, which determines key characteristics and gadget dependencies. The second one, Content, mainly deals with business logic and user interface. The JavaScript API makes it possible for the gadgets to be utilized to their fullest extent.
JavaScript API
First of all, let’s look at what options the JavaScript API opens for OpenSocial Gadgets. It allows the modification and viewing of artifacts, in particular to view and write attributes and acquire the current configuration context and user details. Working with links and the option to discard, add, or design artifacts in a module is also a part of this feature.
Another feature involves viewing and designating the current artifact selection and reacting to when the artifact has been interacted with (opened, selected, saved…)
When it comes to processes that are more compute-intensive, they can be performed by external services that the JavaScript API enables to assign to the task.
Furthermore, the API offers a User picker and an Artifact picker.
Adding and creating OpenSocial Gadgets
All of the features provided by the JavaScript API are utilized by the aforementioned OpenSocial Gadgets to help you get the most out of DOORS Next, save time and simplify work processes.
How can you start using OpenSocial Gadgets? Well, you can either add gadgets that already exist to your Mini Dashboard (a compact dashboard that you can have constantly on hand - pinned to the web UI) or you can create your own OpenSocial Gadgets.
Adding an already existing OpenSocial Gadget to your Mini Dashboard is a relatively simple way to make use of the JavaScript API and OpenSocial Gadget synergy as it requires marginally less effort compared to creating one, however creating your own one has the added benefit of having a gadget which is tailored to your specific needs. If you want to go the way of adding an OpenSocial Gadget to your Mini Dashboard, you will firstly have to work with your browser, then with a requirements module and lastly with the Mini Dashboard itself, this is also where you will spend most time during the process.
Creating a new OpenSocial Gadget can take significant effort and proficiency in JavaScript, especially if it's for complex tasks but the hard work pays off once you can actually utilize it since it will be engineered to do exactly what you need it to do.
While the entire creation process is too complex to be described in this short article, it can be boiled down to six essential steps.
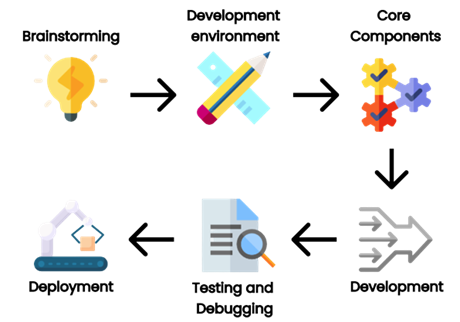
The first step will be the most important for the development as you have to establish the goal for its functionality and what will it be used for. This is crucial because having a clear aim in mind will greatly help you with the creation and implementation process.
For the second step, you will need to acquire the tools and libraries essential for developing your gadgets (e.g. web server, text editor, OpenSocial container). In other words, you will need to put your development environment in order.
The third step includes making the gadget XML file. This will be where the behavior and properties of your OpenSocial Gadget will be determined. CSS, HTML and JavaScript files, the name and description of the gadget, in other words, the core components of your gadget that will ensure that it works.
Now comes the development part of your creation process, as you will have to develop the CSS, HTML and JavaScript files themself, which will be used to make the layout and functionality of your gadget.
For the fifth step you will move onto one of the most critical development stages - testing and debugging, through which you can ensure that your gadget is working as intended and remove any problems that may arise. You can do this in DOORS Next Generation or in an OpenSocial container.
Finally, you should now be at the end of the journey of developing an OpenSocial Gadget and should be able to deploy it to DNG. You will most likely be doing this by uploading it to DOORS Next Generation. Then you can finally include it in a dashboard or wherever you will be able to/need it.
Additional OS related activities
Now the only thing left is to look at some additional useful information that you should know about extending DOORS Next with JavaScript. One such is knowing that you can add OpenSocial Gadgets to the Widget Catalog. This makes life much easier for you as it allows you to quickly and easily search up any gadget, which you can then add to DOORS Next if you wish to.
Another thing is, that a situation can occur when a widget makes an external request (call to an external server). If this happens, what you have to do is enable Cross Origin Resource Sharing if you wish for the request to go through.
Conclusion
In conclusion, if you want to get the most out of IBM® Rational® DOORS® Next Generation, you should definitely consider extending it with JavaScript. Since it already provides a JavaScript API that you can use to optimize and ease workload through OpenSocial Gadgets, extending IBM® Rational® DOORS® Next Generation in ways that we have described will without a shadow of a doubt provide you with a better experience when using the product.
More...

Introduction
When it comes to achieving the goals you set, it is important to have the best tools for the job. If you are already using IBM® Rational® DOORS® or are considering using it, there exists something, which can elevate the experience of using IBM® Rational® DOORS® and allow you to further enhance its already impressive capabilities - IBM® Rational® DOORS® Requirements Management Framework Add-on (also referred to as IRDRMFAO).
Challenges
In this article you will learn about what challenges you might encounter while attaining or managing the highest possible level of process maturity and how you can easily overcome them thanks to IRDMFAO.
- Firstly you can encounter problems when it comes to adopting requirements processes and their execution, especially when they are very complex. This can be a particularly significant issue should all stakeholders be involved in the process.
- When large quantities of requirements need to be analysed, it can be quite a lengthy and difficult process, which is why it needs to be as well optimized as possible.
- Consistency can be another huge obstacle, since it’s difficult to maintain between multiple projects. However, it is crucial for success.
- You may need to reach compliance with ISO 15288 and EIA632 standards. This can prove to be quite problematic
- You can get to a point where your process data model has to be updated on the projects that you are currently working on.
Option to solve it
All of these challenges can add up to be quite a problem. Luckily, IBM® Rational® DOORS® Requirements Management Framework Add-on can help you with every single one. It is a solution, which has been created by industry experts for others in the industry, since it can be utilized by a variety of occupations, e.g. Software Engineers, Hardware Engineers, System Engineers and many more. IRDMFAO is in its essence a requirements management add-on, a solution, whose primary aim it is to help you achieve peak time optimization through getting your project on track with a practice, which is one of the very best ones possible with DOORS. To add to that, IRDMFAO is engineered to help you reach compliance with EIA632 and ISO 15288 standards and CMMI recommendations. IRDRMFAO adds utilities, a process and a data model to DOORS. However the most important thing is that all DOORS commands remain accessible for its users, because there is no interference with the DOORS layout.

Preferred solutions
IRDMFAO provides you with several features, which help overcome the aforementioned challenges, firstly, a RMF Generic Data Model (RMF is an acronym which describes information handled by the product or an action performed by the product). IRDMFAO comes up with a universal data model, however you are not limited to only using this one. As a matter of fact, you will be able to pick from an assortment of module types and relationships, which IRDMFAO provides.
In this example of a RMF model, every box serves as a module type (which serves the purpose of instantiating DOORS formal modules). There are also relationships (verifies, refers to…), which are provided by DOORS link modules and linksets.
In short, every action bolstered by the Requirements Management process handles particular elements of the data model and makes use of varying sorts of relationships and module types (also known as templates). For example, System requirements analysis makes use of UR,IDJ SR modules (UR - Users Requirements; IDJ - Issues & Decisions and Justifications; SR - System Requirements) and the “is justified by”, “satisfies”, “refers to” links.
IRDMFAO does not limit you in using a particular data model. It allows you to customize and adapt it for the needs of your project, since you can decide to only make use of some parts and then, if you see fit, continuously add more. This makes adopting requirements processes and their execution simpler and less time consuming, while also making updates to your data model more intuitive, improving efficiency and consistency in the process.
Regarding the analysis of requirements, IRDMFAO has you covered by implementing specialized facilities that will aid you with management of particularly important requirements, whether they are considered hazardous (Critical requirements) or they are especially important to the project (Key requirements). There are also those that fit into both categories. IRDMFAO offers you “Risk analysis” - a specialized view using which you can assign significance and closely observe the especially problematic requirements. Another dedicated view - “Key requirements list” - allows you to do the same with the requirements you deem to be essential for your project. This will allow you to analyze and work with large volumes of requirements requiring analysis and save you precious time while also making the whole process more efficient.
Last but not least, IRDMFAO provides its check project or module consistency tool to help you maintain peak consistency across your various projects and also modules. It is designed to serve as a precursor for a manual check, as it can notice errors and inconsistencies. You can either use it to monitor through collection of already defined rules or utilize the Integrity Check functionality, in which you can establish your own integrity rules.

Specialized solutions. Approaches, tips
Now for a bit of an inside look, let’s inspect how IRDMFAO works. It enables you to instantaneously switch between two approaches that it uses. The first is the document approach, which you can utilize to view structured information (like chapters, sections, paragraphs) or reach a state of universal and continuous visualisation.
The second, database approach, allows you to define data using attributes and evaluate information, filter only the information that matters to you through filters and view traceability matrices.
To properly utilize the advantages that IRDMFAO offers, you will have to either create a new RMF project or transfer a DOORS project that already exists into a RMF project.
An important aspect of IRDMFAO is PUID (Project Unique Identifier). In its essence, it is used as a reference name of objects handled by the product (RMF objects), for example Requirements. There are two rules for this: firstly, two different objects should not have the same PUID values and secondly, the PUID should remain constant, meaning that even after change (editing the text or relocating the object) is done to it, the PUID should not change.
You do not have to do this manually (although you can), since you can allow IRDMFAO to manage the values automatically. This is another way that IRDMFAO makes your life easier.
Conclusion
All in all, IBM® Rational® DOORS® Requirements Management Framework Add-on (IRDMFAO) is an integrated collection of tools, which is immediately usable and upholds the very best practices used in the industry, in particular regarding systems engineering activities. It can help you maximize your potential by facilitating acceleration in adoption and enactment of requirements processes. Additionally, it guarantees compliance with EIA632 and ISO 15288 standards and SEI-CMM-I recommendations, can improve consistency and drastically simplify analysing huge amounts of requirements (and much more!).

Introduction
The history is an important part of the requirements management tool and the purpose of this article is to explain functions and capabilities of DOORS Next for history maintenance.
The Challenges to Managing History in DOORS Next Generation
On the very basic level history of requirements management items in DOORS Next is organized on artifacts level and is presented as revisions and audit history. This information is accessible for artifacts via ‘Open history’ action in the menu. The first tab you see when you open history is ‘Revisions’, it is splitted on ‘Today’, ‘Yesterday’, ‘Past week’, ‘Past month’ and ‘Earlier’ sections which include different versions of an artifact and baselines of project area or component. When you switch to ‘Audit history’ tab you see only versions of a current artifact with explanation of actions performed on it and changes which were created with information on date and time and author of it. Revisions can be restored to the current state (except revisions which were created with linking operations).
Another source of history of an artifact are system attributes which preserve information on date and time of creation and modification of an artifact and a user who created and modified an artifact. These attributes are updated by the application on creation of an artifact (Created On for date and time of creation and Created By for username) and Modified On and Modified by for the latest modification. Additionally, if you use ReqIF import to add artifacts, attributes with prefix ‘Foreign’ will show you related information from the source.
Of course, a revision list and attributes of a single artifact is not enough to manage requirements history, so versions of artifacts are aggregated to baselines. The first kind of baselines is a DOORS Next baseline, in other words it can be explained as a snapshot which includes certain revisions of artifacts. Baselines are created to preserve some agreed state of requirements.
When we are talking about artifacts revisions It is meaningful to mention that module artifacts revisions are specific - they are created when module structure is changed (set and / or order of included artifacts) or attributes of module itself. So when you edit an artifact in module context without changing position of this artifact in module - you do not create new revision of module automatically. To capture the state of a module you need to create a DOORS Next baseline.
DOORS Next with configuration management capabilities has more options to manage history of requirements. First of all - streams, which allow you to have parallel timelines for different variants of requirements. All requirements in DOORS Next have their initial stream, which is the default timeline for requirements changes. DOORS Next has an option to create a parallel timeline using additional streams, which is mostly used to manage variants of requirements.In this case usually some existing version of requirements is used as an initial state for a new stream. And changes of artifacts in a new stream will not affect the initial stream - revisions of artifacts created in a new stream are visible only in this stream unless the user initiates synchronization. During synchronization the user has options with merging approaches, and one of them is using changesets, which is explained below.
Changesets are another kind of data set in DOORS Next which can be observed in the audit history. There are two types of changesets - user created changeset (name of changeset in this case is specified by user) and internal changeset, which is a reference for changes in the audit history. Internal changesets can be found in the audit history and can be also used as an option to deliver changes across streams. Created by user changesets aggregate small changesets automatically created by DOORS Next, which can be found in audit history and in the merging menu when you deliver changes from one stream to another. Both types of changesets can be found on stream’s page, and if a stream is allowed to be edited only via changesets - it means, users are forced to create a changeset to edit requirements in a stream - a list of changesets of a stream gives you a good representation of history for a stream.
Another functionality to manage history is Global Configuration baseline. When you enable DOORS Next project area for configuration management, links between requirements in different components are created via Global Configuration stream - you need to switch to Global Configuration context to create a link across DOORS Next components and also to see such links. As each component is baselined independently in DOORS Next, in order to preserve cross-component linkage state you need to create a Global Configuration baseline. When you perform this action, baselines are created on each component level automatically and included to a Global Configuration baseline. Switching to this baseline in the future will show you the exact state of linking at the moment of global baseline creation - proper links between proper revisions of artifacts.
Specialized solutions, Approaches, Tips
- As mentioned above, baselines are created on component level (or project area level if project area is not enabled for configuration management). When number of baselines grows, some maintenance of baselines is required - to shorten the list of baselines, some of them need to be archived
- To help users with navigation in list of baselines we provide special widget, which filters from the flat baseline list those baselines which were created in a certain module context

Introduction
Deleting information from any document is something to think about twice may be thrice. But deleting a requirement from a specification is not as simple as deleting a sentence. A requirement is an object which holds not only the specification sentence but other information like name-value pair attributes, history, link information etc.
In this document we will try to explain possible ways to approach how to delete requirements
Challenges
Sometimes it is required to discard some information from the project for various reasons. But even in such cases, when specification information is discarded, there are still some risks as follows:
- It may break the integrity of the overall information map.
- The information piece to be discarded may not be needed in one configuration but may still be critical in others.
- The information piece to be discarded now, may still be an important component of an audit trail
- The information itself may have no value anymore, but the links it bears, my still constitute some value
So when we decide to delete any information from the requirements base, we should be considering several cases. Or somebody has to pre-consider for us.
How to delete requirements from DOORS Next Generation
How can we delete any requirement from DNG? Or what is the best approach to delete requirements from the requirements database?
For the reasons mentioned above, deleting requirements from GUI doesn’t exactly remove the data from the database. It just gets unaccessible. But to keep the integrity intact, any deleted requirement, still occupies a placeholder in the database.
Soft Delete of Artifacts
Since any “delete” operation via the GUI doesn’t cause the physical deletion of the data from the database, and in spite of this result, the data is still permanently unreachable when deleted, may be we can consider a “soft” delete operation.
It is a widely accepted approach to organize requirements in modules within DNG. Like we create/edit requirements within module, we also tend to execute the delete command in modules. This command is called as “Remove Artifact”:

What we are doing with this command is not actually deleting the requirement, but removing it from the module. So it will remain accessible in the base artifacts and folders.

Also, by design, there is a concept of requirement reusability. This means this requirement may coexist in other modules.
This is why, when removing a requirement from a module it is not “deleted” by default. However if the artifact is present only in one module, then there is an option to delete it via “remove” comment as follows:

If the artifact to be removed doesn’t exist in any other module, this option permanently deletes it.
The permanent deletion of the artifact will still leave the artifact on the database for the integrity of the data. But it will not be possible to retrieve this artifact any more.
So we can recommend not to permanently delete any artifact but remove. However there might still be some issues with removing the artifact from the module:
When an artifact is removed from the module, the specification text, its key-value pair attributes, history, all information will remain. Only its link to the module it belongs to will be broken. But there is one important piece of information else which gets broken. The link to other artifacts! In this example we see that the requirement is linked to another requirement in another module. When the artifact is removed from the module, we use that link as well. So when we retrieve it back to the module, it won’t have the link information anymore:

Sometimes our clients may prefer this behavior, sometimes not. For those, of which this is not preferable, we generally consult a “softer” delete operation. We advise to define a boolean attribute called “Deleted” with default value “false”. This attribute is assigned to all artifact types and instead of deleting the artifact, simply change the boolean value from “false” to “true”.
Of course it is not enough to do this. Also we need to define a filter for every view which filters out the “Delete” attribute “true” valued requirements.
Hard Delete of Artifacts
Hard delete of artifacts can be considered as deleting the artifacts with the option “If the artifact is not in other modules, permanently delete it.” selected.

But this will still not be sufficient if the artifact is being used in more than one module. To make sure a hard delete, first remove it from the modules it is being used in.
You can used the information “in modules”

Then, just simply locate the base artifact in the folder structure and select “Delete Artifact” from the context menu.

Upon confirming the deletion it will be permanently deleted:

This operation will still not delete the artifact from other configurations if there are more than one stream and the artifact appears in those streams.
How to clean up requirements
As mentioned above, the requirements even deleted from GUI are not deleted from the database for various reasons. Most of which is to maintain the data integrity and database indices. Theoretically, after every physical deletion of the artifacts a reindexing and database maintenance scripts should be run. This would not make sense for a daily operation done by an end user.
For those artifacts which are permanently deleted from the GUI, there is a repotools command which helps to remove from database as well. This is deleteJFSResources command. However, use it with extra precaution and please review the information in the link below:
https://www.ibm.com/support/pages/deleting-data-permanently-doors-next-generation-project
Summary:
Making use of configurations, streams and modules complicates the deletion concept. We may loose information where we don’t expect. Also we may get results even after properly deleting artifacts. Since they will still be available in other configurations. That is why we generally advise to use the “Deleted” attribute approach and implement the filtering of non-deleted artifacts.

Installation of IBM (Engineering Lifecycle Management) ELM
This article describes our experience in implementing the ELM (Engineering Lifecycle Management) product from IBM.
Introduction
IBM ELM applications are the leading platform for complex product and software development. ELM extends the standard functionality of ALM products. It provides an integrated end-to-end solution that offers complete transparency and tracking of all technical data, through requirements, testing and deployment. ELM optimizes collaboration and communication between all stakeholders, improving decision-making, productivity, and overall product quality. This product has undergone a significant update and has also changed its name from CLM (Collaborative Lifecycle Management) to ELM (Engineering Lifecycle Management).
The main differences between CLM and ELM relate to the change in product names:
- Rational DOORS – in ELM it is called IBM Engineering Requirements Management DOORS Family (DOORS)
- Rational DOORS Next Generation (DNG) – in ELM it is called IBM Engineering Requirements Management DOORS Next (DOORS Next)
- Rational Team Concert (RTC) – in ELM it is called IBM Engineering Workflow Management (EWM)
- Rational Quality Manager (RQM) – in ELM it is called IBM Engineering Test Management (ETM)
- And many more...
Since version 6.0.6.1, the user interface has already changed. However, some applications have not had their names changed, such as Report Builder, Global Configuration Management, Quality Management, etc.
Other differences between CLM and ELM include the fact, that ELM supports different web application servers, operating systems, and databases. For maximum flexibility in adopting new advanced features and to simplify potential future migration to or from:
- IBM ELM on Cloud SaaS
- IBM ELM as a Managed Service
- IBM ELM containerized on RedHat OpenShift, which is currently under development
The current version that we are installing is 7.0.2 SR1 (ifix15). This product is primarily aimed at customers in the fields of healthcare, military, transportation and many other critical areas of industry and manufacturing. Among the main common requirements in these areas of the industry is speed, reliability, flexibility, and security. For the effective and reliable functioning of the ELM solution, initial analysis of requirements and planning is important.
Challenges
After defining the client's requirements (required applications, architecture), the actual deployment of the ELM product is approached. During the design, we consider the client's requirements, adapt the architecture to the already existing infrastructure with the technical requirements of the ELM product. The ELM product supports implementation on Linux (RedHat), Windows and IBM AIX operating systems.
IBM ELM offers several applications, some of which are listed below:
- JTS (Jazz Team Server)
- CCM (Change and Configuration Management)
- RM (Requirements Management)
- QM (Quality Management)
- ENI/RELM (IBM Engineering Lifecycle Optimization - Engineering Insights)
- AM (IBM Engineering Systems Design Rhapsody – Model Management)
- GC (Global Configuration Management)
- LDX (Link Index Provider)
- Jazz Reporting Service, which includes more applications:
- RS (Report Builder)
- DCC (Data Collection Component)
- LQE (Lifecycle Query Engine)
- JAS (Jazz Authorization Server)
- RPENG (Document Builder) – which is implemented as a separate application/system
For large infrastructures, we recommend implementing each application on a separate server. That, however, significantly increases the financial requirements. For fewer lower requirements on ELM, we look for the best possible balance between performance and reliability, taking into consideration their possible financial constraints to achieve the best results. The optimization of the IBM ELM solution can also consist of the fact, that several applications will be deployed on one server at the same time. The implementation of multiple applications on one server is used for less frequently used applications. Based on our experience, we have verified the following logical arrangement of applications on servers (ASX):
- AS1: JTS, LDX, GC
- AS2: QM, CCM
- AS3: DCC, RPENG
- AS4: LQE, RS, RELM
- AS5: RM
For a better understanding of the architecture, the following figure shows a proposal for a possible logical topology:

Preferred Solutions
The recommendation for large customers is to install each application on a separate server, if the technical and financial limitations of the customer's environment allow it. However, this results in increased costs for the server, which consist of installations, licenses, upgrades, and "resources" necessary for the operation of the given solution.
For small and medium-sized customers, based on an initial analysis, we recommend installing less-used applications on a shared server. However, over time, problems with memory and system resource utilization may occur. With a properly designed architecture, these applications can be partitioned without data loss. For detection, prevention of problems and future planning, the deployment of a monitoring system is reccomended.
From the result of the initial analysis, it is determined which application will be installed separately on the server. It is also advisable to install applications on separate servers that the customer uses regularly and contain thousands to millions of requests. Other, less computing and memory-intensive applications can be redistributed so that they can share computing and memory performance.
An essential part of every ELM deployment is the JTS application, which ensures the connection of individual applications. The recommended deployment of ELM packages in the infrastructure is to use IHS (IBM HTTP Server), which is configured as Reverse Proxy.
A necessary part of the solution is the implementation of the database server. The database server stores most of the data, so it is vital to pay extra attention to it when deploying and choosing a suitable product. The basic databases included in the installation include Apache Derby, which is intended primarily for testing purposes with a maximum of 10 users. This database is not intended for production environments and therefore we do not recommend it. Databases suitable for both production and testing include:
- IBM DB2
- Oracle
- Microsoft SQL Server
If the installation is carried out on the cloud, it is preferred to use the DB2 database. In the case of large companies, the Oracle database is more suitable. The use of these databases directly depends on the number of users and the amount of user data.
The use of these databases directly depends on the number of users and the amount of user data.
After the product is installed, we address the implementation of user authentication and security. For basic security, the WebSphere Liberty basic registry is used, which is available immediately after installation, but this option is recommended for testing purposes only. Other authorization options are, for example, the use of the LDAP protocol, which can be supplemented by the installation of JAS (Jazz Authorization Server). With the LDAPS authorization option, users are authorized using a hierarchical user structure. JAS extends the solution with the OAuth2.0 protocol. This solution also offers to authorize third-party applications.
Specialized solutions, approached and tips
From Softacus' point of view, we try to adapt to customers and carry out installations according to their usual standards. Based on the client's requirements, Softacus can work remotely, in the case of customers from critical infrastructure, we can also work on-site. VPN (Virtual Private Network) technologies are used for safe use.
During installations, it is necessary to ensure that installed IBM ELM applications do not have access to environments they are not authorized for. Attention should also be paid to the installation of applications that are listed as "package" (an application with a set of sub-applications to choose from - the client chooses which sub-applications he needs). After installation and subsequent setting of the environment, it is necessary to verify the functionality of the system, which is assisted by the testing team (Softacus).
One of the last steps after performing the installation and securing the server communication is to think about data backup. With customers, it is necessary to think about a "disaster recovery" plan, and it is also necessary to plan regular data backups to secure data against loss or system failure. Monitoring is an essential part of every infrastructure nowadays. Monitoring helps with prediction and improves response to adverse events on servers and applications.
Conclusion
ELM product implementation includes analysis, planning, deployment, and continuous monitoring. At Softacus, we work on improvement and efficiency during the entire course of the solution. It is a continuous and complicated process, during which it is possible to implement new functionalities and extensions into the customers' environment.



